
چقدر زمان میبره؟
چطور ریدایرکت ۳۰۱ با هوش مصنوعی انجام بدیم؟ تو این مقاله از سایت جلال ترابی قصد دارم درمورد این موضوع با شما بیشتر صحبت کنم و باهم این موضوع رو بیشتر بررسی کنیم.
تو دنیای مدیریت سایت و سئو، یکی از چیزایی که خیلی وقتا نادیده گرفته میشه ولی تأثیر عجیبی روی عملکرد سایت داره، همین ریدایرکتهاست؛ مخصوصاً ریدایرکت ۳۰۱. وقتی یه صفحهای پاک میشه یا آدرسش عوض میشه، باید به گوگل و کاربرا بفهمونیم که این صفحه رفته یه جای دیگه. اما موضوع وقتی جدیتر میشه که با سایتهایی طرف باشیم که میلیونها صفحه دارن.
فرض کن یه فروشگاه اینترنتی هست که هزاران محصول داره و هر هفته چندتاش ناموجود یا حذف میشن. یا یه سایت خبری که روزانه دهها مطلب جدید منتشر میکنه و مطالب قدیمیش دیگه کارایی ندارن. یا مثلاً یه سایت آگهی شغلی که آگهیهاش تاریخ انقضا دارن و منقضی میشن. تو این شرایط، اگه بخوای یکییکی بشینی و ریدایرکت بنویسی، نهتنها وقتگیر و طاقتفرساست، بلکه امکان اشتباه و فراموشی هم بالاست.
اینجاست که استفاده از مدلهای هوش مصنوعی (مثل LLMها) میتونه زندگی رو برات راحتتر کنه. چون این ابزارها میتونن خیلی سریع و هوشمند، تشخیص بدن که هر صفحه پاکشده باید به کدوم صفحه زنده و مرتبط هدایت بشه. تو این مقاله میخوایم دقیقاً درباره همین موضوع صحبت کنیم؛ اینکه چطور میتونی با کمک هوش مصنوعی، ریدایرکتهای ۳۰۱ رو بهصورت گسترده و هوشمند انجام بدی و هم سئو سایتتو تقویت کنی، هم تجربه کاربراتو حفظ کنی.
چند تا مثال از جاهایی که باید ریدایرکت رو به صورت گسترده انجام بدی:
یه سایت فروشگاهی که کلی محصولش دیگه موجود نیست یا دیگه فروش نمیره
صفحات قدیمی خبرگزاری ها که دیگه بهدرد نمیخورن یا ارزش تاریخی ندارن
سایت هایی که لیست خدمات یا کسب و کار دارن، ولی اطلاعاتش قدیمی شده
سایتهای استخدامی که آگهیهاش تاریخ انقضا دارن و منقضی میشن
چرا ریدایرکت کردن در مقیاس بزرگ مهمه؟
ریدایرکت کردن درست و گسترده چند تا فایده مهم داره:
تجربه کاربر رو بهتر میکنه
رتبه های سایتت رو جمعوجور و تقویت میکنه
باعث صرفهجویی در بودجه خزش (Crawl Budget) گوگل میشه
شاید به ذهنت برسه که میتونی صفحات قدیمی یا بیارزش رو noindex کنی؛ ولی این کار جلو خزش گوگل رو نمیگیره. یعنی گوگلبات همچنان میاد اون صفحه رو میگرده و این یعنی هدر رفتن بودجه خزیدن مخصوصاً وقتی تعداد صفحات سایت زیاد بشه.
از طرف دیگه، از دید کاربر، وارد شدن به یه صفحه قدیمی و بیفایده، اذیتکنندهست. مثلاً فکر کن یه کاربر روی یه لینک آگهی شغلی کلیک میکنه و میرسه به یه آگهی منقضیشده. خب بهتره اون رو به یه آگهی فعال و مشابه هدایت کنیم تا هم کاربر راضی بمونه، هم سایت اعتبارش حفظ بشه.
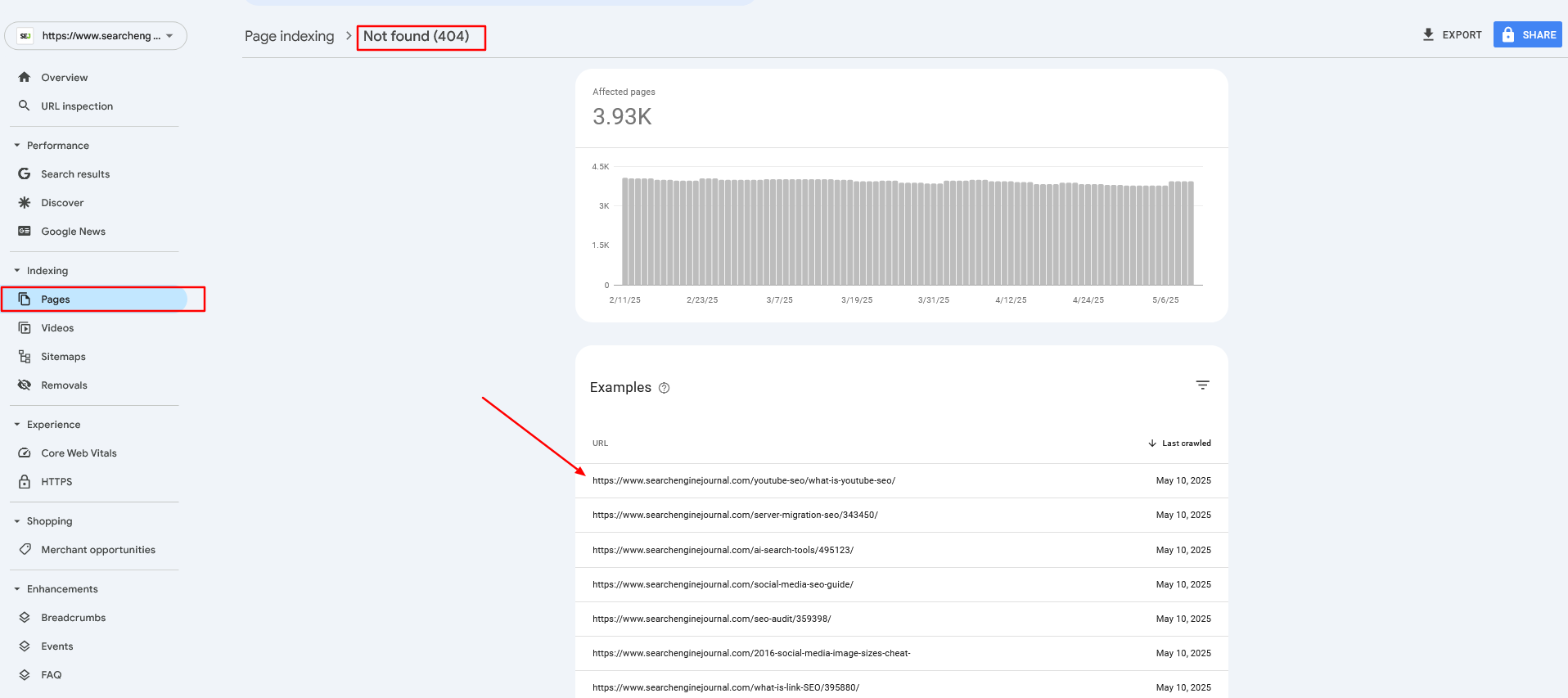
تو سایت Search Engine Journal یا سایت های مشابه (باتوجه به اینکه مقاله به صورت ترجمه روان هست همه اون چیزی که داخل مطلب اومده رو به فارسی روان و عامیانه براتون ترجمه کردم که قابل فهم باشه)، یه مشکلی که خیلی باهاش مواجه میشیم اینه که رباتهای هوش مصنوعی (مثل چتباتها) گاهی لینکهایی میسازن که اصلاً وجود خارجی ندارن! به این اتفاق میگن «توهم» یا hallucination؛ یعنی مدل هوش مصنوعی یه URL خیالی میسازه و مردم هم روش کلیک میکنن، ولی در نهایت میرسن به یه صفحه ۴۰۴.
ما برای اینکه این صفحات خراب رو پیدا کنیم، از گزارشهای Google Analytics 4، سرچ کنسول و گاهی هم لاگهای سرور استفاده میکنیم. وقتی لیست این صفحات ۴۰۴ رو درآوردیم، اونها رو بر اساس اسلاگ مقاله (همون قسمت آخر URL) به نزدیکترین محتوای مرتبط ریدایرکت میکنیم.
وقتی یه چتبات میاد و لینک اشتباهی از سایت ما به کاربر میده، و اون کاربر وارد یه صفحه شکسته میشه، تجربه خوبی براش رقم نمیخوره. پس ما باید سریع این لینکهای خراب رو شناسایی و اصلاح کنیم تا هم کاربران راضی باشن، هم سئو سایت حفظ بشه.
آمادهسازی لیست ریدایرکتها
قبل از هر کاری، اگه با دیتابیسهای برداری (مثل Pinecone) آشنایی نداری، اول یه نگاهی به این آموزش بنداز که چطور میتونی یه پایگاه داده برداری با Pinecone بسازی. (نکته: توی این مثال بهجای کلید category، از primary_category بهعنوان متادیتا استفاده شده.)
فرض ما اینه که بردار (وکتور) همه مقالاتت قبلاً توی دیتابیس Pinecone با نام article-index-vertex ذخیره شدن. یعنی دیتابیس آمادهست و فقط باید URLهایی که نیاز به ریدایرکت دارن رو براش بفرستی.
برای این کار، یه فایل CSV بساز (مثل فایل نمونهای که تو مقاله هست) و توش لیست URLهایی که میخوای ریدایرکت بشن رو وارد کن. این URLها میتونن:
صفحات قدیمی باشن که تصمیم گرفتی حذفشون کنی (prune)
یا لینکهای ۴۰۴ که توی سرچ کنسول یا گوگل آنالیتیکس ۴ گزارش شدن
بعد این لیست میره تو فرآیند تشخیص صفحه جایگزین با استفاده از هوش مصنوعی. یعنی قراره LLM یا مدل زبانی بیاد و تشخیص بده هر کدوم از این URLها بهتره به کدوم صفحه موجود توی سایت ریدایرکت بشن.

اگه موقع ساخت دیتابیس برداری (وکتورها) برای مقالاتت، یه متادیتای به اسم primary_category هم وارد کرده باشی، خیلی به کارت میاد. چون میتونی موقع پیدا کردن مقصد مناسب برای ریدایرکت، فقط از بین مقالات همدسته انتخاب کنی. اینطوری دقت پیشنهادها خیلی بالاتر میره.
حالا اگه یه صفحه ۴۰۴ داری که عنوان مقالهاش مشخص نیست (مثلاً چون پاک شده یا اطلاعات ناقصه)، نگران نباش. اسکریپت بهجای عنوان، میاد و کلمات موجود در آدرس URL (همون اسلاگ) رو استخراج میکنه و از اونها بهعنوان ورودی برای پیدا کردن مقاله مشابه استفاده میکنه.
مثلاً URL /guide/seo-beginner-checklist داره؟ اسکریپت میاد از کلمات seo، beginner و checklist استفاده میکنه تا بگرده و ببینه کدوم مقاله زنده توی سایت بیشترین شباهت معنایی رو داره.
ساخت ریدایرکتها با استفاده از Google Vertex AI
برای اینکه فرآیند ریدایرکتسازی با هوش مصنوعی انجام بشه، باید از Google Vertex AI استفاده کنی. اینم مراحل کار:
اول از همه، اطلاعات دسترسی به Google API (یعنی فایل credentials) رو از پنل گوگل دانلود کن.
اسم فایل رو بذار
config.jsonتا اسکریپت بتونه راحت باهاش کار کنه.حالا اسکریپتی که تو مقاله هست + فایل نمونه URLها رو بذار توی یه پوشه توی محیط Jupyter Lab.
اسکریپت رو اجرا کن و صبر کن تا خروجی ریدایرکتها برات ساخته بشه.
اسکریپت خودش میره URLها رو با استفاده از مدل زبان گوگل بررسی میکنه و برای هر کدوم یه مقصد مناسب پیشنهاد میده. یعنی دیگه لازم نیست دستی بشینی بگردی ببینی چی رو به کجا ریدایرکت کنی! نمونه کد پایتون زیر رو ببین:
import os
import time
import logging
from urllib.parse import urlparse
import re
import pandas as pd
from pandas.errors import EmptyDataError
from typing import Optional, List, Dict, Any
from google.auth import load_credentials_from_file
from google.cloud import aiplatform
from google.api_core.exceptions import GoogleAPIError
from pinecone import Pinecone, PineconeException
from vertexai.language_models import TextEmbeddingModel, TextEmbeddingInput
# Import tenacity for retry mechanism. Tenacity provides a decorator to add retry logic
# to functions, making them more robust against transient errors like network issues or API rate limits.
from tenacity import retry, wait_exponential, stop_after_attempt, retry_if_exception_type
# For clearing output in Jupyter (optional, keep if running in Jupyter).
# This is useful for interactive environments to show progress without cluttering the output.
from IPython.display import clear_output
# ─── USER CONFIGURATION ───────────────────────────────────────────────────────
# Define configurable parameters for the script. These can be easily adjusted
# without modifying the core logic.
INPUT_CSV = "redirect_candidates.csv" # Path to the input CSV file containing URLs to be redirected.
# Expected columns: "URL", "Title", "primary_category".
OUTPUT_CSV = "redirect_map.csv" # Path to the output CSV file where the generated redirect map will be saved.
PINECONE_API_KEY = "YOUR_PINECONE_KEY" # Your API key for Pinecone. Replace with your actual key.
PINECONE_INDEX_NAME = "article-index-vertex" # The name of the Pinecone index where article vectors are stored.
GOOGLE_CRED_PATH = "config.json" # Path to your Google Cloud service account credentials JSON file.
EMBEDDING_MODEL_ID = "text-embedding-005" # Identifier for the Vertex AI text embedding model to use.
TASK_TYPE = "RETRIEVAL_QUERY" # The task type for the embedding model. Try with RETRIEVAL_DOCUMENT vs RETRIEVAL_QUERY to see the difference.
# This influences how the embedding vector is generated for optimal retrieval.
CANDIDATE_FETCH_COUNT = 3 # Number of potential redirect candidates to fetch from Pinecone for each input URL.
TEST_MODE = True # If True, the script will process only a small subset of the input data (MAX_TEST_ROWS).
# Useful for testing and debugging.
MAX_TEST_ROWS = 5 # Maximum number of rows to process when TEST_MODE is True.
QUERY_DELAY = 0.2 # Delay in seconds between successive API queries (to avoid hitting rate limits).
PUBLISH_YEAR_FILTER: List[int] = [] # Optional: List of years to filter Pinecone results by 'publish_year' metadata.
# If empty, no year filtering is applied.
LOG_BATCH_SIZE = 5 # Number of URLs to process before flushing the results to the output CSV.
# This helps in saving progress incrementally and managing memory.
MIN_SLUG_LENGTH = 3 # Minimum length for a URL slug segment to be considered meaningful for embedding.
# Shorter segments might be noise or less descriptive.
# Retry configuration for API calls (Vertex AI and Pinecone).
# These parameters control how the `tenacity` library retries failed API requests.
MAX_RETRIES = 5 # Maximum number of times to retry an API call before giving up.
INITIAL_RETRY_DELAY = 1 # Initial delay in seconds before the first retry.
# Subsequent retries will have exponentially increasing delays.
# ─── SETUP LOGGING ─────────────────────────────────────────────────────────────
# Configure the logging system to output informational messages to the console.
logging.basicConfig(
level=logging.INFO, # Set the logging level to INFO, meaning INFO, WARNING, ERROR, CRITICAL messages will be shown.
format="%(asctime)s %(levelname)s %(message)s" # Define the format of log messages (timestamp, level, message).
)
# ─── INITIALIZE GOOGLE VERTEX AI ───────────────────────────────────────────────
# Set the GOOGLE_APPLICATION_CREDENTIALS environment variable to point to the
# service account key file. This allows the Google Cloud client libraries to
# authenticate automatically.
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = GOOGLE_CRED_PATH
try:
# Load credentials from the specified JSON file.
credentials, project_id = load_credentials_from_file(GOOGLE_CRED_PATH)
# Initialize the Vertex AI client with the project ID and credentials.
# The location "us-central1" is specified for the AI Platform services.
aiplatform.init(project=project_id, credentials=credentials, location="us-central1")
logging.info("Vertex AI initialized.")
except Exception as e:
# Log an error if Vertex AI initialization fails and re-raise the exception
# to stop script execution, as it's a critical dependency.
logging.error(f"Failed to initialize Vertex AI: {e}")
raise
# Initialize the embedding model once globally.
# This is a crucial optimization for "Resource Management for Embedding Model".
# Loading the model takes time and resources; doing it once avoids repeated loading
# for every URL processed, significantly improving performance.
try:
GLOBAL_EMBEDDING_MODEL = TextEmbeddingModel.from_pretrained(EMBEDDING_MODEL_ID)
logging.info(f"Text Embedding Model '{EMBEDDING_MODEL_ID}' loaded.")
except Exception as e:
# Log an error if the embedding model fails to load and re-raise.
# The script cannot proceed without the embedding model.
logging.error(f"Failed to load Text Embedding Model: {e}")
raise
# ─── INITIALIZE PINECONE ──────────────────────────────────────────────────────
# Initialize the Pinecone client and connect to the specified index.
try:
pinecone = Pinecone(api_key=PINECONE_API_KEY)
index = pinecone.Index(PINECONE_INDEX_NAME)
logging.info(f"Connected to Pinecone index '{PINECONE_INDEX_NAME}'.")
except PineconeException as e:
# Log an error if Pinecone initialization fails and re-raise.
# Pinecone is a critical dependency for finding redirect candidates.
logging.error(f"Pinecone init error: {e}")
raise
# ─── HELPERS ───────────────────────────────────────────────────────────────────
def canonical_url(url: str) -> str:
"""
Converts a given URL into its canonical form by:
۱. Stripping query strings (e.g., `?param=value`) and URL fragments (e.g., `#section`).
۲. Handling URL-encoded fragment markers (`%23`).
۳. Preserving the trailing slash if it was present in the original URL's path.
This ensures consistency with the original site's URL structure.
Args:
url (str): The input URL.
Returns:
str: The canonicalized URL.
"""
# Remove query parameters and URL fragments.
temp = url.split('?', 1)[0].split('#', 1)[0]
# Check for URL-encoded fragment markers and remove them.
enc_idx = temp.lower().find('%23')
if enc_idx != -1:
temp = temp[:enc_idx]
# Determine if the original URL path ended with a trailing slash.
has_slash = urlparse(temp).path.endswith('/')
# Remove any trailing slash temporarily for consistent processing.
temp = temp.rstrip('/')
# Re-add the trailing slash if it was originally present.
return temp + ('/' if has_slash else '')
def slug_from_url(url: str) -> str:
"""
Extracts and joins meaningful, non-numeric path segments from a canonical URL
to form a "slug" string. This slug can be used as text for embedding when
a URL's title is not available.
Args:
url (str): The input URL.
Returns:
str: A hyphen-separated string of relevant slug parts.
"""
clean = canonical_url(url) # Get the canonical version of the URL.
path = urlparse(clean).path # Extract the path component of the URL.
segments = [seg for seg in path.split('/') if seg] # Split path into segments and remove empty ones.
# Filter segments based on criteria:
# - Not purely numeric (e.g., '123' is excluded).
# - Length is greater than or equal to MIN_SLUG_LENGTH.
# - Contains at least one alphanumeric character (to exclude purely special character segments).
parts = [seg for seg in segments
if not seg.isdigit()
and len(seg) >= MIN_SLUG_LENGTH
and re.search(r'[A-Za-z0-9]', seg)]
return '-'.join(parts) # Join the filtered parts with hyphens.
# ─── EMBEDDING GENERATION FUNCTION ─────────────────────────────────────────────
# Apply retry mechanism for GoogleAPIError. This makes the embedding generation
# more resilient to transient issues like network problems or Vertex AI rate limits.
@retry(
wait=wait_exponential(multiplier=INITIAL_RETRY_DELAY, min=1, max=10), # Exponential backoff for retries.
stop=stop_after_attempt(MAX_RETRIES), # Stop retrying after a maximum number of attempts.
retry=retry_if_exception_type(GoogleAPIError), # Only retry if a GoogleAPIError occurs.
reraise=True # Re-raise the exception if all retries fail, allowing the calling function to handle it.
)
def generate_embedding(text: str) -> Optional[List[float]]:
"""
Generates a vector embedding for the given text using the globally initialized
Vertex AI Text Embedding Model. Includes retry logic for API calls.
Args:
text (str): The input text (e.g., URL title or slug) to embed.
Returns:
Optional[List[float]]: A list of floats representing the embedding vector,
or None if the input text is empty/whitespace or
if an unexpected error occurs after retries.
"""
if not text or not text.strip():
# If the text is empty or only whitespace, no embedding can be generated.
return None
try:
# Use the globally initialized model to get embeddings.
# This is the "Resource Management for Embedding Model" optimization.
inp = TextEmbeddingInput(text, task_type=TASK_TYPE)
vectors = GLOBAL_EMBEDDING_MODEL.get_embeddings([inp], output_dimensionality=768)
return vectors[0].values # Return the embedding vector (list of floats).
except GoogleAPIError as e:
# Log a warning if a GoogleAPIError occurs, then re-raise to trigger the `tenacity` retry mechanism.
logging.warning(f"Vertex AI error during embedding generation (retrying): {e}")
raise # The `reraise=True` in the decorator will catch this and retry.
except Exception as e:
# Catch any other unexpected exceptions during embedding generation.
logging.error(f"Unexpected error generating embedding: {e}")
return None # Return None for non-retryable or final failed attempts.
# ─── MAIN PROCESSING FUNCTION ─────────────────────────────────────────────────
def build_redirect_map(
input_csv: str,
output_csv: str,
fetch_count: int,
test_mode: bool
):
"""
Builds a redirect map by processing URLs from an input CSV, generating
embeddings, querying Pinecone for similar articles, and identifying
suitable redirect candidates.
Args:
input_csv (str): Path to the input CSV file.
output_csv (str): Path to the output CSV file for the redirect map.
fetch_count (int): Number of candidates to fetch from Pinecone.
test_mode (bool): If True, process only a limited number of rows.
"""
# Read the input CSV file into a Pandas DataFrame.
df = pd.read_csv(input_csv)
required = {"URL", "Title", "primary_category"}
# Validate that all required columns are present in the DataFrame.
if not required.issubset(df.columns):
raise ValueError(f"Input CSV must have columns: {required}")
# Create a set of canonicalized input URLs for efficient lookup.
# This is used to prevent an input URL from redirecting to itself or another input URL,
# which could create redirect loops or redirect to a page that is also being redirected.
input_urls = set(df["URL"].map(canonical_url))
start_idx = 0
# Implement resume functionality: if the output CSV already exists,
# try to find the last processed URL and resume from the next row.
if os.path.exists(output_csv):
try:
prev = pd.read_csv(output_csv)
except EmptyDataError:
# Handle case where the output CSV exists but is empty.
prev = pd.DataFrame()
if not prev.empty:
# Get the last URL that was processed and written to the output file.
last = prev["URL"].iloc[-1]
# Find the index of this last URL in the original input DataFrame.
idxs = df.index[df["URL"].map(canonical_url) == last].tolist()
if idxs:
# Set the starting index for processing to the row after the last processed URL.
start_idx = idxs[0] + 1
logging.info(f"Resuming from row {start_idx} after {last}.")
# Determine the range of rows to process based on test_mode.
if test_mode:
end_idx = min(start_idx + MAX_TEST_ROWS, len(df))
df_proc = df.iloc[start_idx:end_idx] # Select a slice of the DataFrame for testing.
logging.info(f"Test mode: processing rows {start_idx} to {end_idx-1}.")
else:
df_proc = df.iloc[start_idx:] # Process all remaining rows.
logging.info(f"Processing rows {start_idx} to {len(df)-1}.")
total = len(df_proc) # Total number of URLs to process in this run.
processed = 0 # Counter for successfully processed URLs.
batch: List[Dict[str, Any]] = [] # List to store results before flushing to CSV.
# Iterate over each row (URL) in the DataFrame slice to be processed.
for _, row in df_proc.iterrows():
raw_url = row["URL"] # Original URL from the input CSV.
url = canonical_url(raw_url) # Canonicalized version of the URL.
# Get title and category, handling potential missing values by defaulting to empty strings.
title = row["Title"] if isinstance(row["Title"], str) else ""
category = row["primary_category"] if isinstance(row["primary_category"], str) else ""
# Determine the text to use for generating the embedding.
# Prioritize the 'Title' if available, otherwise use a slug derived from the URL.
if title.strip():
text = title
else:
slug = slug_from_url(raw_url)
if not slug:
# If no meaningful slug can be extracted, skip this URL.
logging.info(f"Skipping {raw_url}: insufficient slug context for embedding.")
continue
text = slug.replace('-', ' ') # Prepare slug for embedding by replacing hyphens with spaces.
# Attempt to generate the embedding for the chosen text.
# This call is wrapped in a try-except block to catch final failures after retries.
try:
embedding = generate_embedding(text)
except GoogleAPIError as e:
# If embedding generation fails even after retries, log the error and skip this URL.
logging.error(f"Failed to generate embedding for {raw_url} after {MAX_RETRIES} retries: {e}")
continue # Move to the next URL.
if not embedding:
# If `generate_embedding` returned None (e.g., empty text or unexpected error), skip.
logging.info(f"Skipping {raw_url}: no embedding generated.")
continue
# Build metadata filter for Pinecone query.
# This helps narrow down search results to more relevant candidates (e.g., by category or publish year).
filt: Dict[str, Any] = {}
if category:
# Split category string by comma and strip whitespace for multiple categories.
cats = [c.strip() for c in category.split(",") if c.strip()]
if cats:
filt["primary_category"] = {"$in": cats} # Filter by categories present in Pinecone metadata.
if PUBLISH_YEAR_FILTER:
filt["publish_year"] = {"$in": PUBLISH_YEAR_FILTER} # Filter by specified publish years.
filt["id"] = {"$ne": url} # Exclude the current URL itself from the search results to prevent self-redirects.
# Define a nested function for Pinecone query with retry mechanism.
# This ensures that Pinecone queries are also robust against transient errors.
@retry(
wait=wait_exponential(multiplier=INITIAL_RETRY_DELAY, min=1, max=10),
stop=stop_after_attempt(MAX_RETRIES),
retry=retry_if_exception_type(PineconeException), # Only retry if a PineconeException occurs.
reraise=True # Re-raise the exception if all retries fail.
)
def query_pinecone_with_retry(embedding_vector, top_k_count, pinecone_filter):
"""
Performs a Pinecone index query with retry logic.
"""
return index.query(
vector=embedding_vector,
top_k=top_k_count,
include_values=False, # We don't need the actual vector values in the response.
include_metadata=False, # We don't need the metadata in the response for this logic.
filter=pinecone_filter # Apply the constructed metadata filter.
)
# Attempt to query Pinecone for redirect candidates.
try:
res = query_pinecone_with_retry(embedding, fetch_count, filt)
except PineconeException as e:
# If Pinecone query fails after retries, log the error and skip this URL.
logging.error(f"Failed to query Pinecone for {raw_url} after {MAX_RETRIES} retries: {e}")
continue # Move to the next URL.
candidate = None # Initialize redirect candidate to None.
score = None # Initialize relevance score to None.
# Iterate through the Pinecone query results (matches) to find a suitable candidate.
for m in res.get("matches", []):
cid = m.get("id") # Get the ID (URL) of the matched document in Pinecone.
# A candidate is suitable if:
# ۱. It exists (cid is not None).
# ۲. It's not the original URL itself (to prevent self-redirects).
# ۳. It's not another URL from the input_urls set (to prevent redirecting to a page that's also being redirected).
if cid and cid != url and cid not in input_urls:
candidate = cid # Assign the first valid candidate found.
score = m.get("score") # Get the relevance score of this candidate.
break # Stop after finding the first suitable candidate (Pinecone returns by relevance).
# Append the results for the current URL to the batch.
batch.append({"URL": url, "Redirect Candidate": candidate, "Relevance Score": score})
processed += 1 # Increment the counter for processed URLs.
msg = f"Mapped {url} → {candidate}"
if score is not None:
msg += f" ({score:.4f})" # Add score to log message if available.
logging.info(msg) # Log the mapping result.
# Periodically flush the batch results to the output CSV.
if processed % LOG_BATCH_SIZE == 0:
out_df = pd.DataFrame(batch) # Convert the current batch to a DataFrame.
# Determine file mode: 'a' (append) if file exists, 'w' (write) if new.
mode = 'a' if os.path.exists(output_csv) else 'w'
# Determine if header should be written (only for new files).
header = not os.path.exists(output_csv)
# Write the batch to the CSV.
out_df.to_csv(output_csv, mode=mode, header=header, index=False)
batch.clear() # Clear the batch after writing to free memory.
if not test_mode:
# clear_output(wait=True) # Uncomment if running in Jupyter and want to clear output
clear_output(wait=True)
print(f"Progress: {processed} / {total}") # Print progress update.
time.sleep(QUERY_DELAY) # Pause for a short delay to avoid overwhelming APIs.
# After the loop, write any remaining items in the batch to the output CSV.
if batch:
out_df = pd.DataFrame(batch)
mode = 'a' if os.path.exists(output_csv) else 'w'
header = not os.path.exists(output_csv)
out_df.to_csv(output_csv, mode=mode, header=header, index=False)
logging.info(f"Completed. Total processed: {processed}") # Log completion message.
if __name__ == "__main__":
# This block ensures that build_redirect_map is called only when the script is executed directly.
# It passes the user-defined configuration parameters to the main function.
build_redirect_map(INPUT_CSV, OUTPUT_CSV, CANDIDATE_FETCH_COUNT, TEST_MODE)
وقتی برای اولین بار اسکریپت رو اجرا میکنی، چون گزینه TEST_MODE روی حالت True تنظیم شده، فقط روی ۵ تا از آدرسها اجرا میشه. این یعنی یه تست اولیه انجام میده تا مطمئن بشی همهچی درست کار میکنه.
بعد از اجرای اسکریپت، یه فایل جدید به اسم redirect_map.csv ساخته میشه که توش پیشنهادهای ریدایرکت نوشته شده؛ یعنی آدرسهای خراب و مقصدهایی که مدل هوش مصنوعی برای اونها پیشنهاد داده.
اگه دیدی همهچی درست اجرا شده و مشکلی نداری، کافیه مقدار TEST_MODE رو از True به False تغییر بدی تا اسکریپت روی همهی URLها اجرا بشه و برات یه لیست کامل از ریدایرکتها تولید کنه.
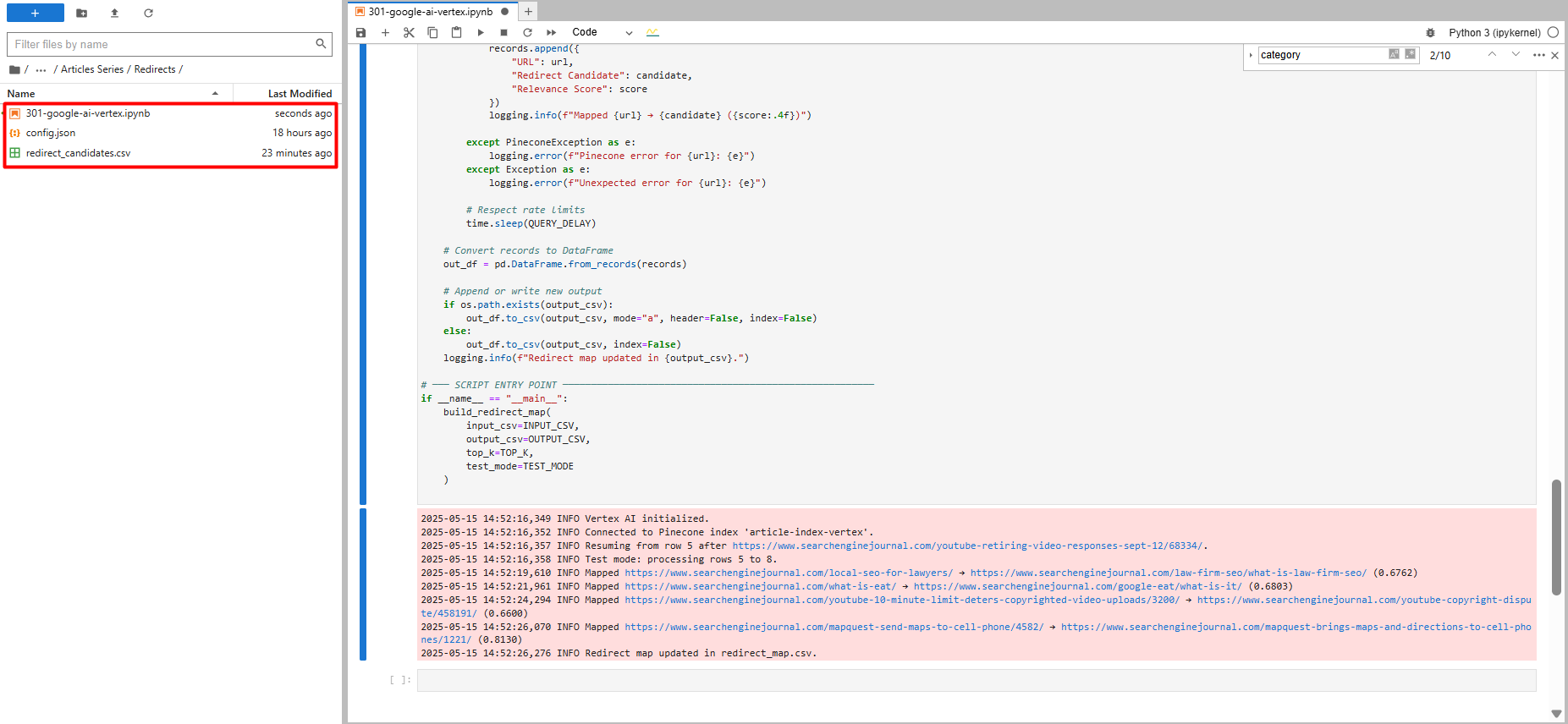
اگه به هر دلیلی وسط کار اجرای اسکریپت قطع بشه (مثلاً سیستم خاموش بشه یا اینترنت بره)، نگران نباش. اسکریپت طوری نوشته شده که وقتی دوباره اجراش کنی، از همون جایی که متوقف شده ادامه میده.
چطوری این کارو میکنه؟ میاد خروجی قبلی (redirect_map.csv) رو میخونه، میبینه آخرین URLی که پردازش کرده چی بوده، و از همون بعدی شروع میکنه. اینطوری وقتت تلف نمیشه و کارهای تکراری انجام نمیدی.
جلوگیری از ریدایرکت اشتباه و حلقه بینهایت
اسکریپت یه کار مهم دیگه هم میکنه: هر پیشنهادی که از دیتابیس برای مقصد ریدایرکت پیدا میکنه، با لیست URLهایی که تو CSV ورودی هست مقایسه میکنه. این کار برای اینه که یه URL خراب رو به یه URL دیگه که خودش قراره حذف یا ریدایرکت بشه وصل نکنه.
اگه این بررسی انجام نشه، ممکنه بهطور ناخواسته یه حلقه ریدایرکت بینهایت درست بشه. یعنی یه URL به یه URL دیگه منتقل بشه و اون یکی هم به اولی برگرده یا به یه URL حذفشده بره. ولی این اسکریپت جلو این اتفاق رو کامل میگیره.

حالا که فایل redirect_map.csv ساخته شده و پیشنهادهای ریدایرکت آمادهست، میتونی خیلی راحت این لیست رو وارد افزونه یا بخش مدیریت ریدایرکتهات در سیستم مدیریت محتوا (CMS) سایتت بکنی. همین! دیگه لازم نیست دستی دنبال مقصد مناسب برای هر صفحه خراب بگردی.
چند مثال واقعی از تطبیق هوشمندانه مدل:
یه مقاله خبری قدیمی مربوط به سال ۲۰۱۳ با عنوان:
“YouTube Retiring Video Responses on September 12”
توسط مدل به یه مقاله جدیدتر و مرتبط از سال ۲۰۲۲ وصل شد با عنوان:
“YouTube Adopts Feature From TikTok – Reply To Comments With A Video”
که از نظر موضوعی هم کاملاً مرتبطه.یا یه URL دیگه به اسم
/what-is-eat/تونست به صورت دقیق و ۱۰۰٪ درست وصل بشه به آدرس:/google-eat/what-is-it/
این یعنی مدل واقعاً فهم محتوا داره، نه اینکه فقط شباهت ظاهری واژهها رو بررسی کنه. این سطح از ریدایرکت دقیق، دستی خیلی سخت و وقتگیره، ولی با این روش خیلی سریع و هوشمند انجام میشه.
چرا نتیجهها اینقدر دقیق بودن؟ فقط به خاطر هوش مصنوعی گوگل نیست!
درسته که مدل Google Vertex AI خیلی قدرتمنده، ولی دقت بالا و پیشنهادهای عالی که گرفتیم فقط به خاطر کیفیت خود مدل نیست. بخش زیادی از نتیجه خوب، به انتخاب درست پارامترها مربوطه.
مثال واقعی از تفاوت در پارامترها:
فرض کن مقالهای داریم درباره خبر قدیمی یوتیوب. وقتی از پارامتر RETRIEVAL_DOCUMENT برای ساخت وکتور استفاده کردیم، مدل اومد و مقاله جدیدی با عنوان “YouTube Expands Community Posts to More Creators” رو به عنوان مقصد ریدایرکت پیشنهاد داد. این مقاله خوبه، اما اون یکی که قبلاً پیشنهاد داده بود (یعنی: “Reply To Comments With A Video”) خیلی مرتبطتر و دقیقتر بود.
یا مثلاً برای URL /what-is-eat/ هم وقتی تنظیمات اشتباه بود، یه مقاله عمومیتر و دورتر پیشنهاد شد با عنوان:
“Reimagining EEAT To Drive Higher Sales And Search Visibility”
درحالیکه پیشنهاد بهتر، مقاله دقیقتر و مستقیمتر:/google-eat/what-is-it/ بود.
چطور میتونیم مقالههای جدیدتر رو در اولویت بذاریم؟
اگه بخوای فقط از بین مقالههای تازهتر ریدایرکت پیشنهاد داده بشه، میتونی از فیلتر publish_year توی Pinecone استفاده کنی (البته اگه این فیلد رو توی متادیتای وکتورها ذخیره کرده باشی).
کافیه تو کدت، متغیر PUBLISH_YEAR_FILTER رو مقداردهی کنی. مثلاً:
PUBLISH_YEAR_FILTER = [2023, 2024, 2025]
با این کار فقط مقالههایی که تو این سالها منتشر شدن بررسی میشن و نتیجههای بهروزتری میگیری.
انجام همین کار با مدل OpenAI (مقایسه)
حالا قراره همین فرآیند رو با مدل text-embedding-ada-002 از OpenAI انجام بدیم تا تفاوت نتیجه با گوگل رو مقایسه کنیم. این کار نشون میده که هر مدل خروجی متفاوتی میده و شاید بسته به نوع محتوا و سایتت، یکی بهتر از اون یکی باشه.
چطور انجامش بدیم؟
خیلی ساده:
یه فایل نوتبوک جدید (مثلاً تو JupyterLab) تو همون پوشه بساز
کدی که برای OpenAI نوشته شده رو توش کپی کن
اجراش کن و خروجیها رو با گوگل مقایسه کن
مقایسه کیفیت خروجی OpenAI با Google Vertex AI
درسته که خروجی مدل OpenAI text-embedding-ada-002 قابل قبول و «خوب» بهنظر میرسه، ولی واقعیت اینه که کیفیت نهایی اون هنوز به پای خروجی مدل Google Vertex AI نمیرسه. یعنی چی؟ یعنی مدل OpenAI هم پیشنهادهای قابل قبولی میده، ولی دقت معنایی، میزان نزدیکی محتوا، و ارتباط مفهومی در پیشنهادهای گوگل بالاتر بوده.
مقایسه در جدول زیر کاملاً مشخصه:
| URL | Google Vertex | OpenAI |
|---|---|---|
| /what-is-eat/ | /google-eat/what-is-it/ | /۵-things-you-can-do-right-now-to-improve-your-eat-for-google/408423/ |
| /local-seo-for-lawyers/ | /law-firm-seo/what-is-law-firm-seo/ | /legal-seo-conference-exclusively-for-lawyers-spa/528149/ |
تحلیل جدول:
تو مورد اول، گوگل دقیقترین و مستقیمترین تطابق رو داده. OpenAI یه مقاله مفید ولی غیرمستقیم رو پیشنهاد داده.
تو مورد دوم، گوگل یه مقاله تخصصی درباره سئوی شرکتهای حقوقی پیشنهاد داده، ولی OpenAI مقالهای درباره یه کنفرانس معرفی کرده که کمتر کاربردیه برای ریدایرکت مفهومی.
هزینه Google Vertex AI در مقابل OpenAI – آیا ارزشش رو داره؟
وقتی پای سئو وسطه، کیفیت خروجی خیلی مهمتر از هزینهست. درسته که Google Vertex AI تقریباً سه برابر گرونتر از مدل OpenAI حساب میشه، ولی از نظر من (نویسنده مقاله)، استفاده از Vertex خیلی بهصرفهتر و باکیفیتتره.
چرا Google Vertex بهتره؟
دقت و ارتباط معنایی خروجیها واقعاً بالاتره
نیازی به بازبینی و ویرایش دستی خیلی کمتر میشه
صرفهجویی مستقیم در زمان تیم سئو و محتوا
مثلاً تو تجربه خودم، با حدود ۰.۰۴ دلار تونستم ۲۰ هزار URL رو پردازش کنم. این یعنی:
برای ۱۰۰ هزار آدرس میشه حدود ۰.۲۰ دلار
و برای ۱ میلیون URL نهایتاً حدود ۲ دلار
عملاً خیلی ارزونه، حتی اگر اسمش “گرانتر از OpenAI” باشه.
اگه دنبال روش رایگانتری هستی…
اگه واقعاً نمیخوای هیچ هزینهای بابت API بدی، میتونی از مدلهای اوپنسورس مثل:
BERT
LLaMA
که توی سایت Hugging Face هستن استفاده کنی.
این مدلها رایگان هستن ولی یه نکته مهم دارن:
باید خودت از نظر سختافزاری (کارت گرافیک، RAM و …) قوی باشی
تمام بردارها (وکتورها) رو باید خودت تولید کنی و بعد داخل Pinecone یا هر دیتابیس برداری دیگهای بریزی
یعنی عملاً هزینه از API نمیدی، ولی باید هزینه و زمان صرف قدرت پردازشی و اجرای مدلها بکنی. این راه بیشتر برای پروژههای بلندمدت یا کسانیه که دسترسی به سرور قدرتمند دارن.
